Here's yet another "ultimate Elixir CI" blog post. We haven't had one for quite some time. But on a more serious note we have some unique ideas, so continue reading and I'm sure you'll get some inspiration for your development workflows.
When a post like this comes out, I check it out to see if I can learn about a new tool to use in pursuit of higher code quality, but the thing I get most excited about is reducing the time it takes to get that CI checkmark for my or someone else's PR. Unfortunately, mostly I realize it's a twist to an older approach with everything else pretty much the same. I have yet to see one offering a different caching solution. Usually, it's the same approach presented in the GitHub Actions docs. I saw some downside in their workflows which I'll explain below, but ours won't be spared of criticism either. As with anything, the goal is to find the balance, and as our name suggests, we strive to create optimum solutions, so here's one on us.
A quick reminder: even though here we use GitHub Actions, the principles are also applicable to other types of CIs.
But first, what's a CI?
This article is about a software development practice. For other uses, see Informant. (🙄 I rewatched The Wire recently)
During the development of new features, there comes a time when the developer submits the code for review. At one stage of the code review process, project maintainers want to make sure that the newly written code doesn't introduce any regressions to existing features. That is, unless they blindly trust the phrase "it works on my machine". Then, if they are satisfied with the code quality they can merge the pull request and potentially proceed with a release process if there is a continuous delivery (CD) system in place.
CI (continuous integration) system automates the testing process, enabling everyone involved to see which commit introduced a regression early in the workflow, before the reviewer even starts the review process. It frees the project maintainer from having to run the tests (either manually or using an automated system) on their machine, conserving their energy to focus on other aspects of code quality and the business domain. Machines are better at those boring, repetitive tasks, anyway. Let them have it, so they don't start the uprise.
Now, if you don't write and run tests in your Elixir applications, you probably have bigger issues to worry about. So make sure to handle that before going further.
Old approach
If you're just starting to build your CI, you might not be interested in this part and can jump straight to the New approach section.
The old approach consists of having all the checks as steps of one job of GitHub Actions workflow. That means commands for the code checks are running one after the other. For example, you might be running the formatter, then dialyzer, and finally, tests.
The good thing about this approach is that the code gets compiled once and then used for each of these steps. You have to make sure, though, that the commands are running in the test environment, either by prefixing the command with
MIX_ENV=test or by setting the :preferred_cli_env option to ensure compilation is done only in one environment, otherwise you'd unnecessarily compile in both dev and test environments.The bad thing is that if one of the commands fails, at that moment you don't know yet whether the subsequent commands will fail also. So, you might fix the formatting and push the code only to find out minutes later that the tests failed too. Then you have to fix them and repeat the process.
The other bad thing is the caching of dependencies. To understand why, you need to know how the caching works in GitHub Actions. You can learn about that in the official documentation, but here's the gist of it.
When setting up caching, you provide a key to be used for saving and restoring it. Once saved, cache with specified key cannot be updated. It gets purged after 7 days if it's not used, or if the total cache size goes above the limit. But you shouldn't rely on that. The key doesn't have to match exactly, though. You have an option of using multiple restore keys for partial matching.
Here's an example from the documentation:
[yml]- name: Cache node modules
uses: actions/cache@v3
with:
path: ~/.npm
key: npm-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
npm-
The thing is, that might work for JS community where each run of
npm install command causes the lock file to change, making frequent cache updates.More importantly, when using Elixir, we don't only want to cache dependencies (
deps directory), but also the compiled code (_build). When our application code changes, the cache key isn't updated, meaning, as time goes by, there will be more changed files that will need to be compiled, making the CI slower and slower. For an active repo, the cache will never get purged, so the only way to reduce the number of files to be compiled each time is to update the lock file, or manually change the cache key, none of which is ideal. Theoretically, the cache might never be refreshed, but in practice, you would probably do an update of dependencies every few months. But still, you need to unnecessarily wait for all the files that were changed since the cache was created to (re)compile.The issue is multiplied if you extract each command into its own job to enable running them in parallel, but without improving to the caching strategy. That will cause each command to compile all the files in the app that were changed since the cache was created, which for big codebases can be too much, unnecessarily increasing the cost of CI. Not only that, it's hard to maintain those workflows because GitHub Actions doesn't have a good mechanism for the reuse of jobs and steps. You can learn how to deal with that in Maintaining GitHub Actions workflows.
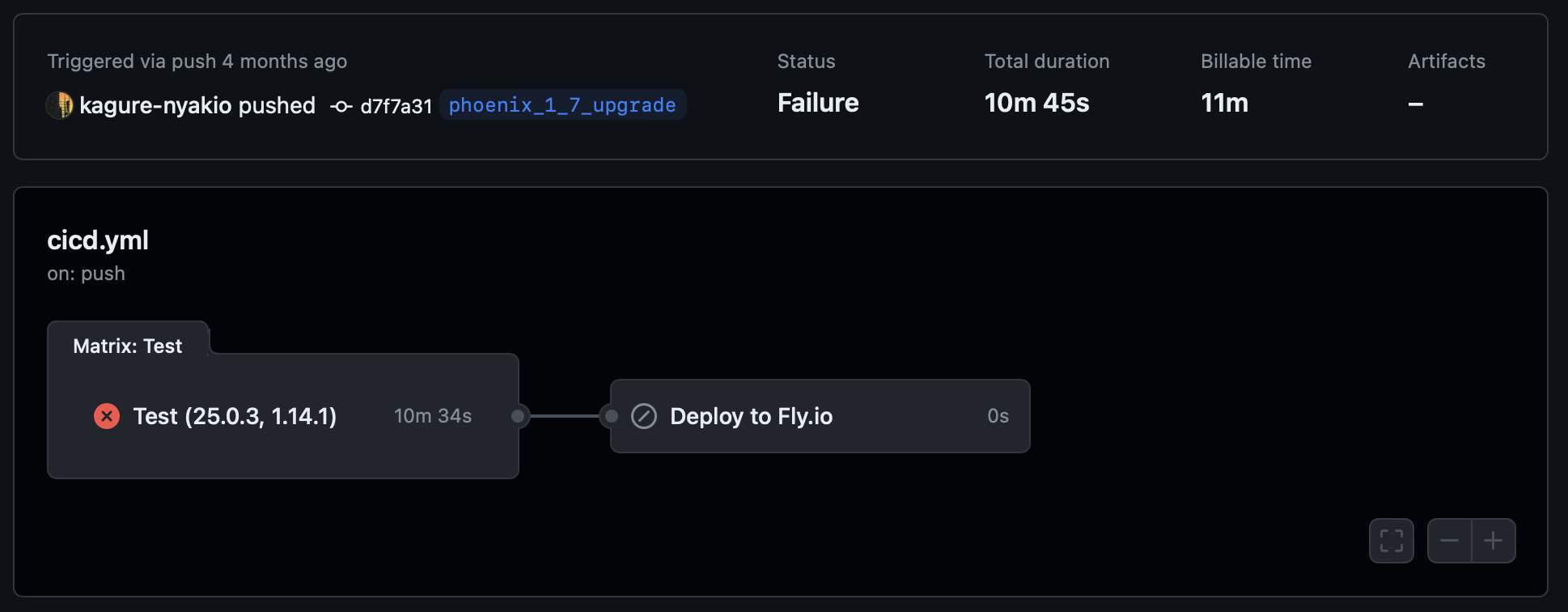
New approach
I won't go too much into explaining what we do. One Look is Worth A Thousand Words.
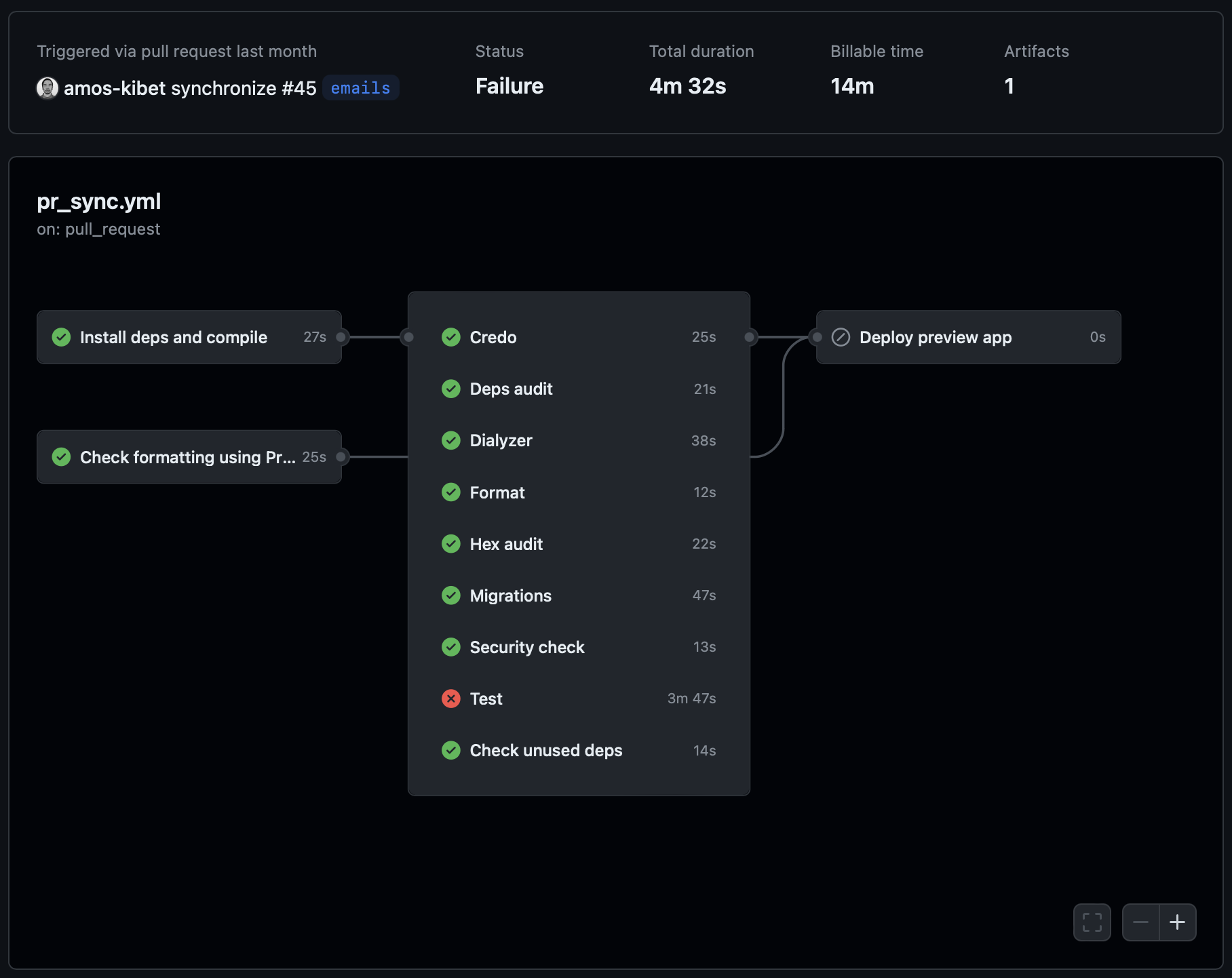
- The work is parallelized so the time waiting for the CI is shortened.
- Compiling is done only once in a job, and then cached for use by all the other jobs.
- Jobs that don't depend on the cache run independently.
- Every job is running in the test environment to prevent triggering unnecessary compilation.
- It's possible to see from the list of commits which check has failed.
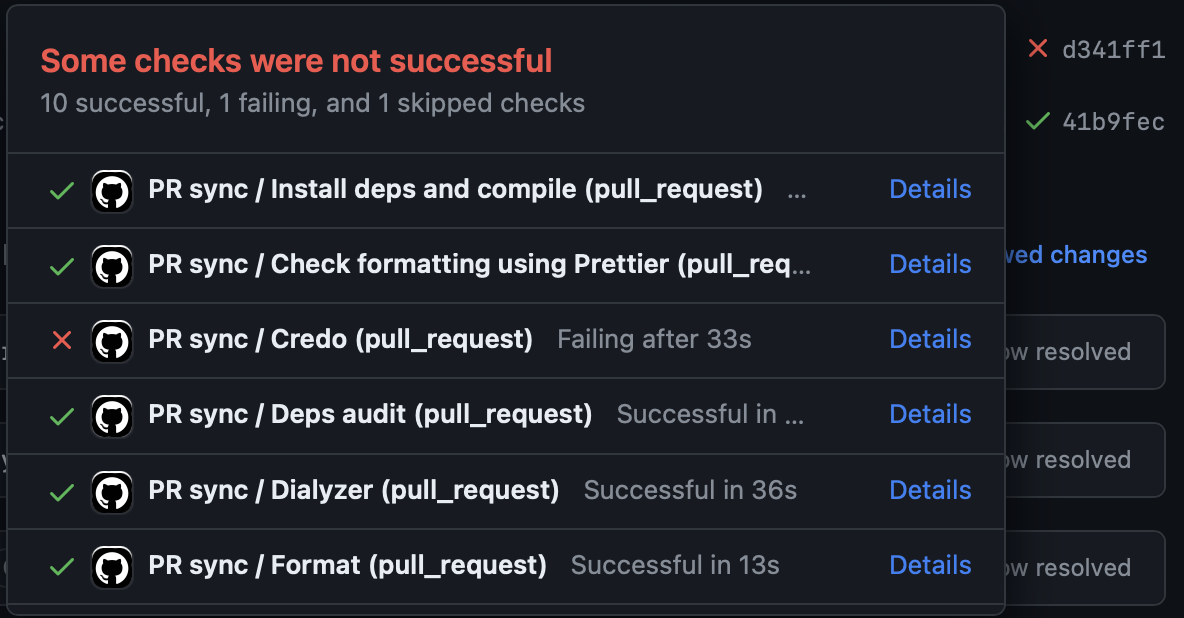
Those were the benefits. Now let's talk about the detriments of this approach:
- It's using too much cache. There's a 10 GB limit in GitHub Actions, and the old cache is automatically evicted. So, that doesn't worry me much.
- Issues could arise from using cache instead of running a fresh build in CI. The old approach is susceptible to this as well, but I guess this one is more because it provides better caching. What we could do to improve this is to disable using cache on retries. Or we could manually delete the cache from the GitHub Actions UI. We didn't need either of those yet.
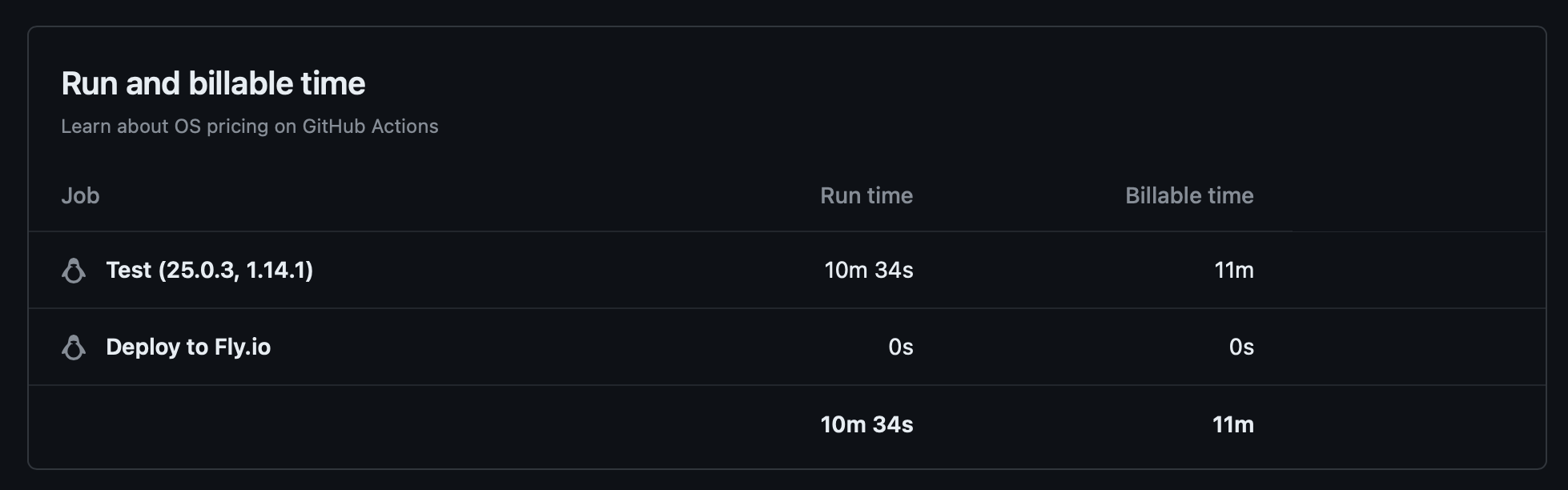
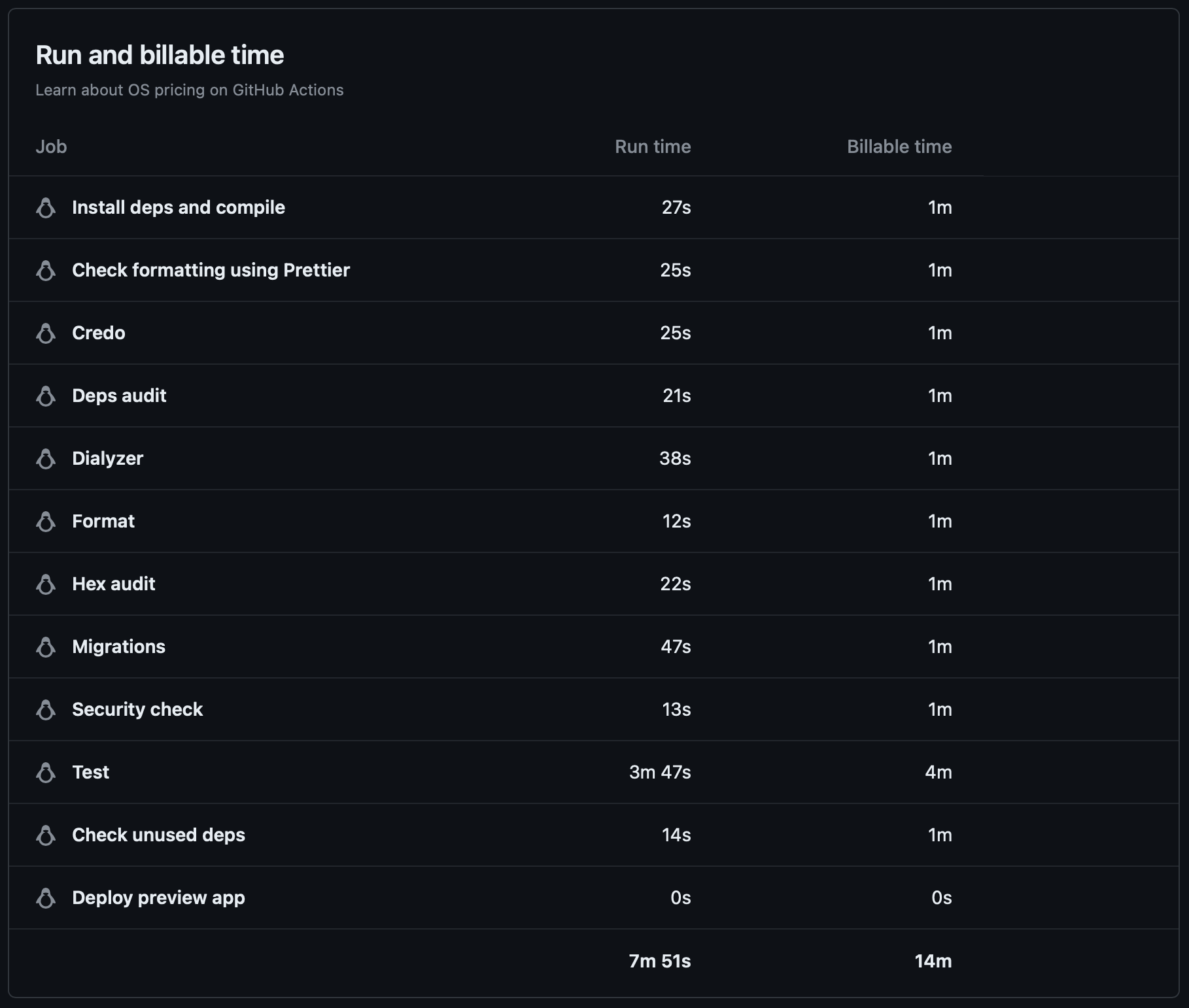
- It's more expensive. The workflow running this way uses more runner minutes. You'd expect it's because of the containers being set up, but GitHub doesn't bill us for the time it takes to set up their environment. Thanks, GitHub! They get us the other way, though: when rounding minutes, they are ceiling, and that's what makes all the difference. Even if the job finishes in 10 seconds, it's billed as a whole minute, so if you have 10 steps that are each running in 10 to 30 seconds, you'll be billed 10 minutes even though the whole workflow might have been completed in one job running under 5 minutes. You can see that most of our jobs are running for less than half a minute, but we get billed for the whole minute. In our projects, we still go under the quota, so it wasn't a concert for us, but it's something to be aware of. If you use a macOS runner and/or have a pretty active codebase, you will notice the greater cost.
Now that we have cleared that, let's see some code.
We solved the caching part by using git commit hash as the key and using a restore key that enables restoring cache, while still creating a new one every time the workflow runs.
[elixir][
uses: "actions/cache@v3",
with:
[
key: "mix-${{ github.sha }}",
path: ~S"""
_build
deps
""",
"restore-keys": ~S"""
mix-
"""
]
]
Our solution for the jobs parallelization is harder to show:
[elixir]defp pr_workflow do
[
[
name: "PR",
on: [
pull_request: [
branches: ["main"],
]
],
jobs: [
compile: compile_job(),
credo: credo_job(),
deps_audit: deps_audit_job(),
dialyzer: dialyzer_job(),
format: format_job(),
hex_audit: hex_audit_job(),
migrations: migrations_job(),
prettier: prettier_job(),
sobelow: sobelow_job(),
test: test_job(),
unused_deps: unused_deps_job()
]
]
]
end
defp compile_job do
elixir_job(“Install deps and compile”,
steps: [
[
name: “Install Elixir dependencies”,
env: [MIX_ENV: “test”],
run: “mix deps.get”
],
[
name: “Compile”,
env: [MIX_ENV: “test”],
run: “mix compile”
]
]
)
end
defp credo_job do
elixir_job(“Credo”,
needs: :compile,
steps: [
[
name: “Check code style”,
env: [MIX_ENV: “test”],
run: “mix credo –strict”
]
]
)
end
Another benefit of splitting the workflow into multiple jobs is that the cache is still written even if some of the checks fail. Before, everything would still need to be recompiled (and PLT files for dialyzer created - I know, I know, I've been there) every time the workflow runs after failing.
But hold on a minute. Are we writing our GitHub Actions workflows in Elixir?! That can't be right…
It's not magic, it's a script we wrote to maintain GitHub Actions more easily.
Full example of a complex workflow we made for our phx.tools project is available here: https://github.com/optimumBA/phx.tools/blob/main/.github/github_workflows.ex, and here you can see it in action(s): https://github.com/optimumBA/phx.tools/actions.
Running the checks locally
We don't rely only on GitHub Actions for the code checks. Usually, just before committing the code, we run the checks locally. That way we find errors more quickly and don't unnecessarily waste our GitHub Actions minutes.
To execute them all one after the other, we run a convenient
mix ci command. It's an alias we add to our apps that locally runs the same commands that are run in GitHub Actions.[elixir]defp aliases do
[
...
ci: [
"deps.unlock --check-unused",
"deps.audit",
"hex.audit",
"sobelow --config .sobelow-conf",
"format --check-formatted",
"cmd --cd assets npx prettier -c ..",
"credo --strict",
"dialyzer",
"ecto.create --quiet",
"ecto.migrate --quiet",
"test --cover --warnings-as-errors",
]
...
]
When one of these commands fails, we run it again in isolation and try fixing it while rerunning the command until the issue is fixed. Then we run
mix ci again until every command passes.To run each of these commands without having to prefix with
MIX_ENV=test, you can pass the :preferred_cli_env option to the project/0:[elixir]def project do
[
...
preferred_cli_env: [
ci: :test,
coveralls: :test,
"coveralls.detail": :test,
"coveralls.html": :test,
credo: :test,
dialyzer: :test,
sobelow: :test
],
...
]
end
Usually in our projects, we also like to check whether all migrations can be rolled back. To achieve that, we run the command
mix ecto.rollback --all --quiet after these. Create a Makefile in the root of your project with the following content:[bash]ci: mix ci MIX_ENV=test mix ecto.rollback --all --quiet
and run
make ci.Need help?
You're probably reading this because you're just starting to build your CI pipeline, or maybe you're looking for ways to make the existing one better. In any case, we're confident we can find ways to improve your overall development experience.
Whether you're just testing out your idea with a proof-of-concept (PoC), building a minimum viable product (MVP), or want us to extend and refactor your app that's already serving your customers, I'm sure we can help you out. You can reach us at projects@optimum.ba.
This was a post from our Elixir DevOps series.