If you were wondering why you saw the topbar loading for ~5 seconds every time you deployed to Fly.io, you're at the right place. We need to talk about deployment strategies. Typically, there are several, but Fly.io supports these:
immediaterollingbluegreencanary
The complexity and cost go from low to high as we go down the list. The default option is rolling. That means, your machines will be replaced by new ones one by one. In case you only have one machine, it will be destroyed before there's a new one that can handle requests. That's why you're waiting to be reconnected whenever you deploy. You can read more about these deployment strategies at https://fly.io/docs/apps/deploy/#deployment-strategy.
We're using the blue-green deployment strategy as it strikes a balance between the benefits, cost, and ease of setup.
If you're using volumes, I have to disappoint you as the blue-green strategy doesn't work with them yet, but Fly.io plans to support that in the future.
Setup
You need to configure at least one health check to use the
bluegreen strategy. I won't go into details. You can find more at https://fly.io/docs/reference/configuration/#http_service-checks.Here's a configuration we use:
[toml][[http_service.checks]] grace_period = "10s" interval = "30s" method = "GET" path = "/health" timeout = "5s"
Then, add
strategy = "bluegreen" under [deploy] in your fly.toml file:[toml][deploy] strategy = "bluegreen"
and run
fly deploy.That's it! You probably expected the setup to be more complex than this. So did I!
Conclusion
While Fly.io is moving you from a blue to a green machine, your websocket connection will be dropped, but it will quickly reestablish. You shouldn't even notice it unless you have your browser console open or you're navigating through pages during the deployment.
One thing you should keep in mind, though, is that your client-side state (form data) might be lost if you don't address that explicitly.
Another thing to think about is the way you run Ecto migrations. In case you're dropping tables or columns, you might want to do that in multiple stages. For example, you might introduce changes in the code so you stop depending on specific columns or tables and deploy that change. After that, you can have subsequent deployment for the structural changes of the database. That way, both blue and green machines will have the same expectations regarding the database structure.
The future will bring us more options for deployment. Recently, Chris McCord teased us with hot deploys.
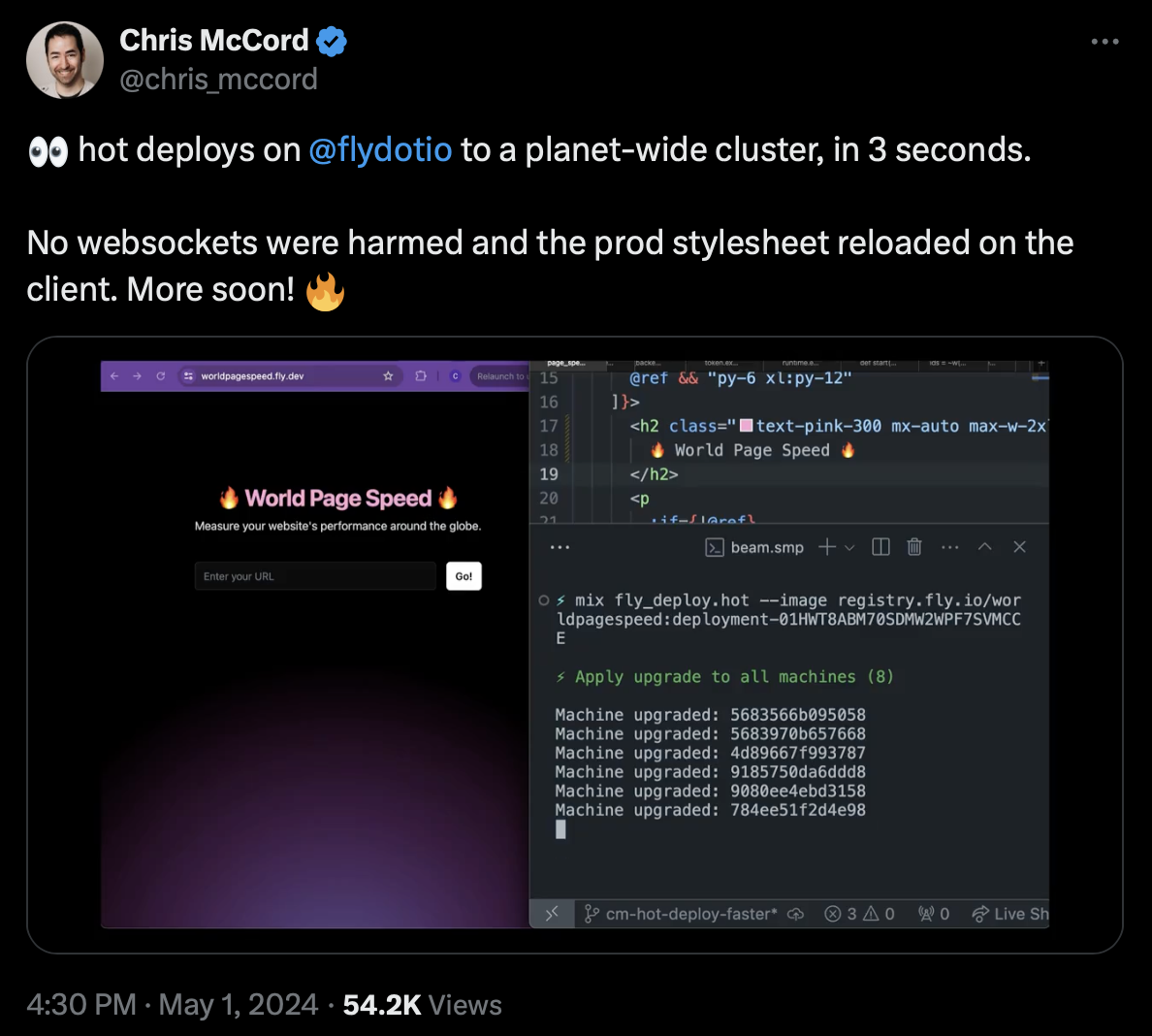
Can't wait for this!
This was a post from our Elixir DevOps series.